这篇文章上次修改于 1053 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
前言
本文主要参考定制bcc/ebpf在android平台上实现基于dwarf的用户态栈回溯
对其中的内容做一点扩展,并对具体的代码修改进行详细说明
在阅读本文之前建议先过一下参考文章
效果示意:
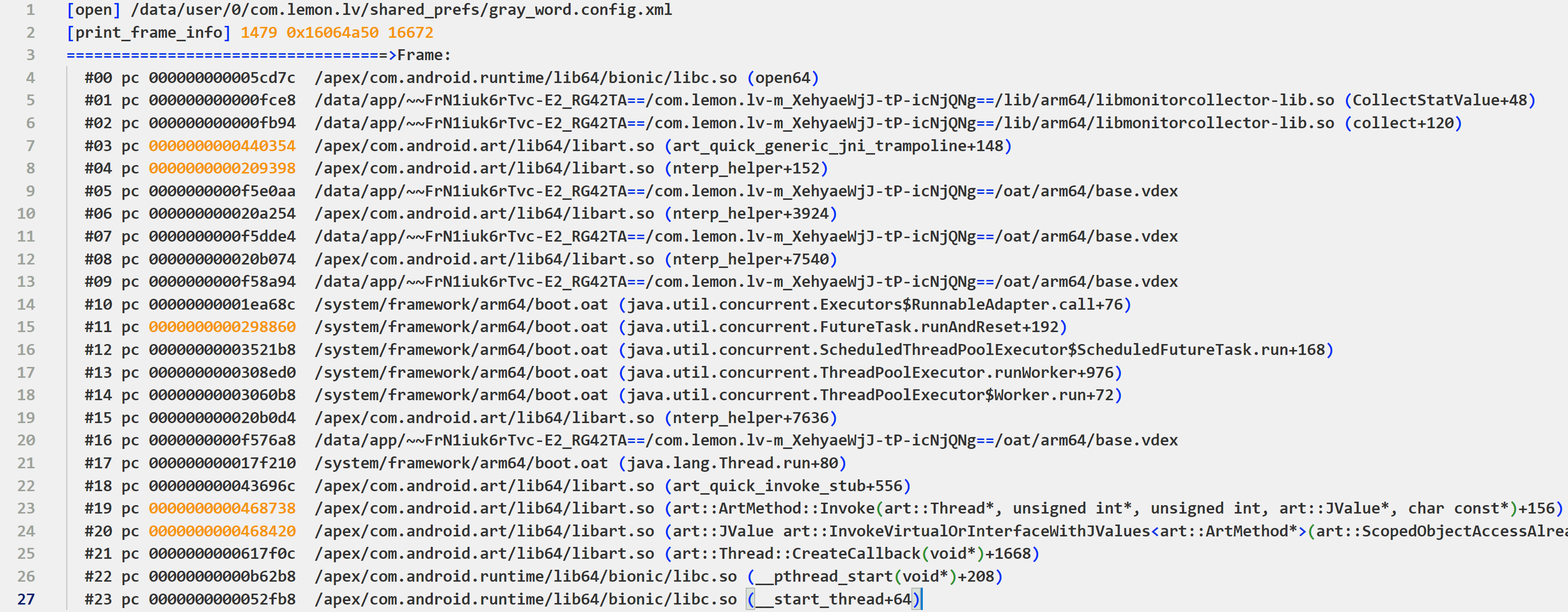
环境
仅供参考,不同设备可能存在差异
- Pixel 4XL
- TP1A.220905.004 Android 13
- Ubuntu 20.04
步骤
不具体说明AOSP同步过程,请参考博客中的其他文章
理解参考文章
首先知道一件事:
so编译时即使指定了-fomit-frame-pointer选项,simpleperf也能正确打印出堆栈信息借鉴simpleperf
先看看simpleperf测试效果吧!
simpleperf是基于dwarf的.eh_frame节进行栈回溯的
到底如何实现的呢?根据参考文章可以知道关键函数是UnwindCallChain
函数主要6步:
- 获取sp地址
- 获取maps信息
- 获取寄存器信息
通过上述信息初始化Unwinder
- 注意这里还用到了用户空间的栈数据,即传入的
stack和stack_size变量
- 注意这里还用到了用户空间的栈数据,即传入的
- 解析获取栈信息
- 遍历栈信息

同样的,我们也可以使用类似的方法去获取相关信息,根据参考文章,具体做法如下:
- 目标进程pid、用户空间栈数据和寄存器信息由bcc发送给守护进程
- maps信息通过读取
/proc/{pid}/maps获取 - 初始化Unwinder
- 解析获取栈信息
- 返回栈信息给bcc
获取寄存器信息和用户空间栈数据
PERF_SAMPLE_REGS_USER用于指示内核将用户空间发生事件时(这里为系统调用)的寄存器信息以PERF_RECORD_SAMPLE记录类型传送给用户空间
PERF_SAMPLE_STACK_USER用于指示内核将用户空间发生事件时(这里为系统调用)的栈空间片段数据以PERF_RECORD_SAMPLE记录类型传送给用户空间
内核对应代码具体位于private/msm-google/kernel/events/core.c的perf_output_sample函数中
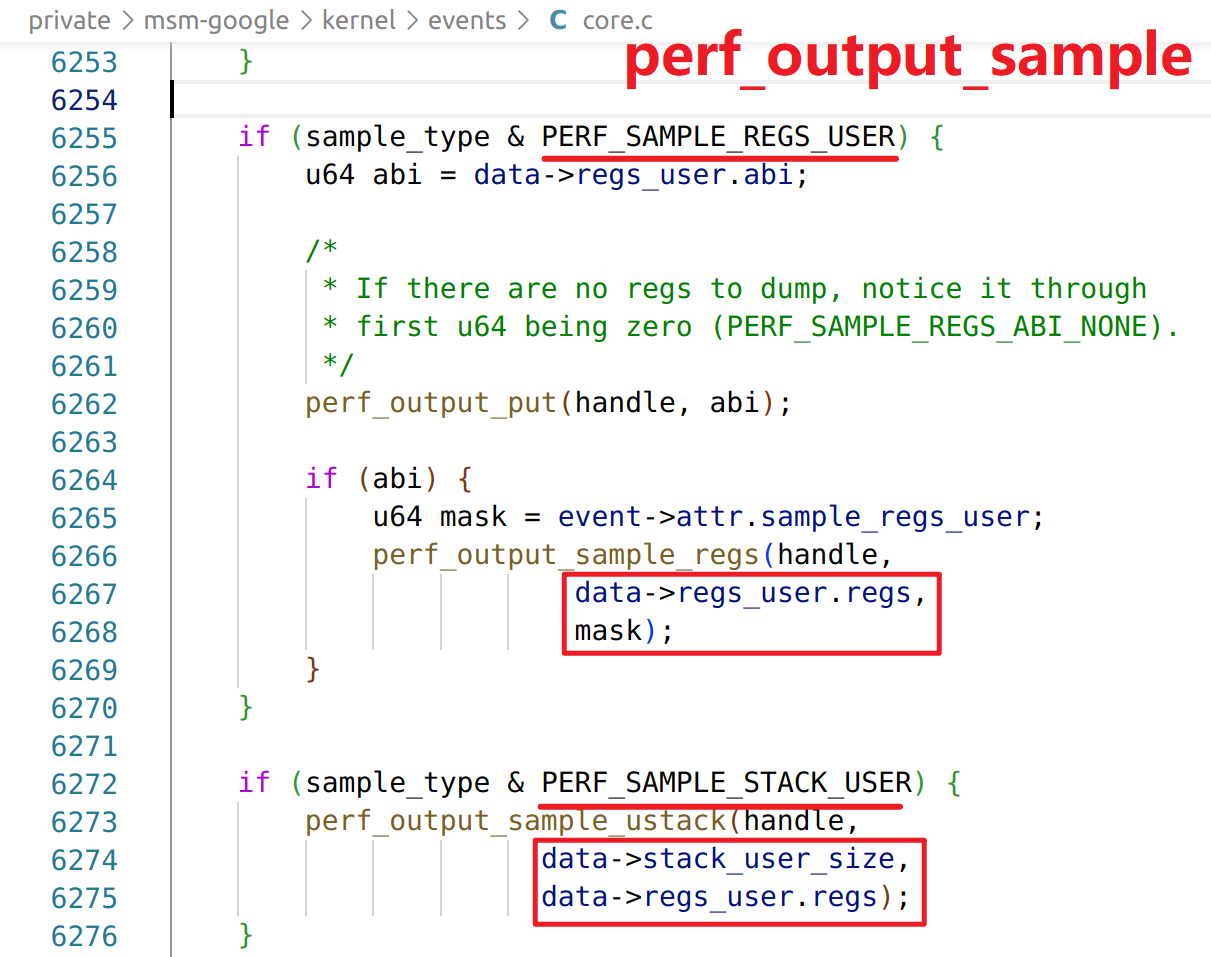
具体来说就是bcc在调用perf_event_open的时候,会给内核发数据,数据中有一项就是用于告诉内核返回数据时要携带何种类型的数据
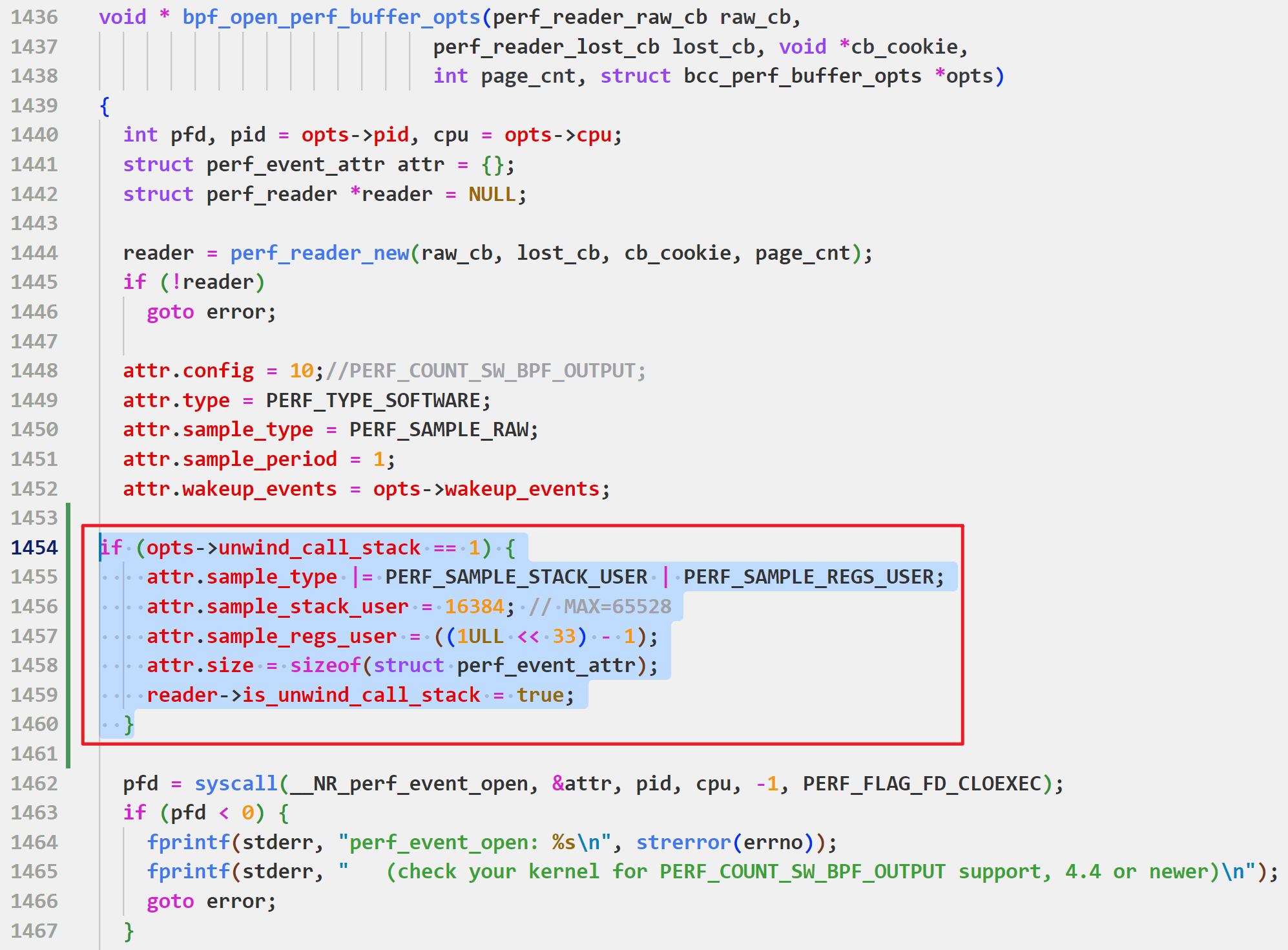
具体来说就是如图所示的attr.sample_type在控制,bcc默认只有PERF_SAMPLE_RAW
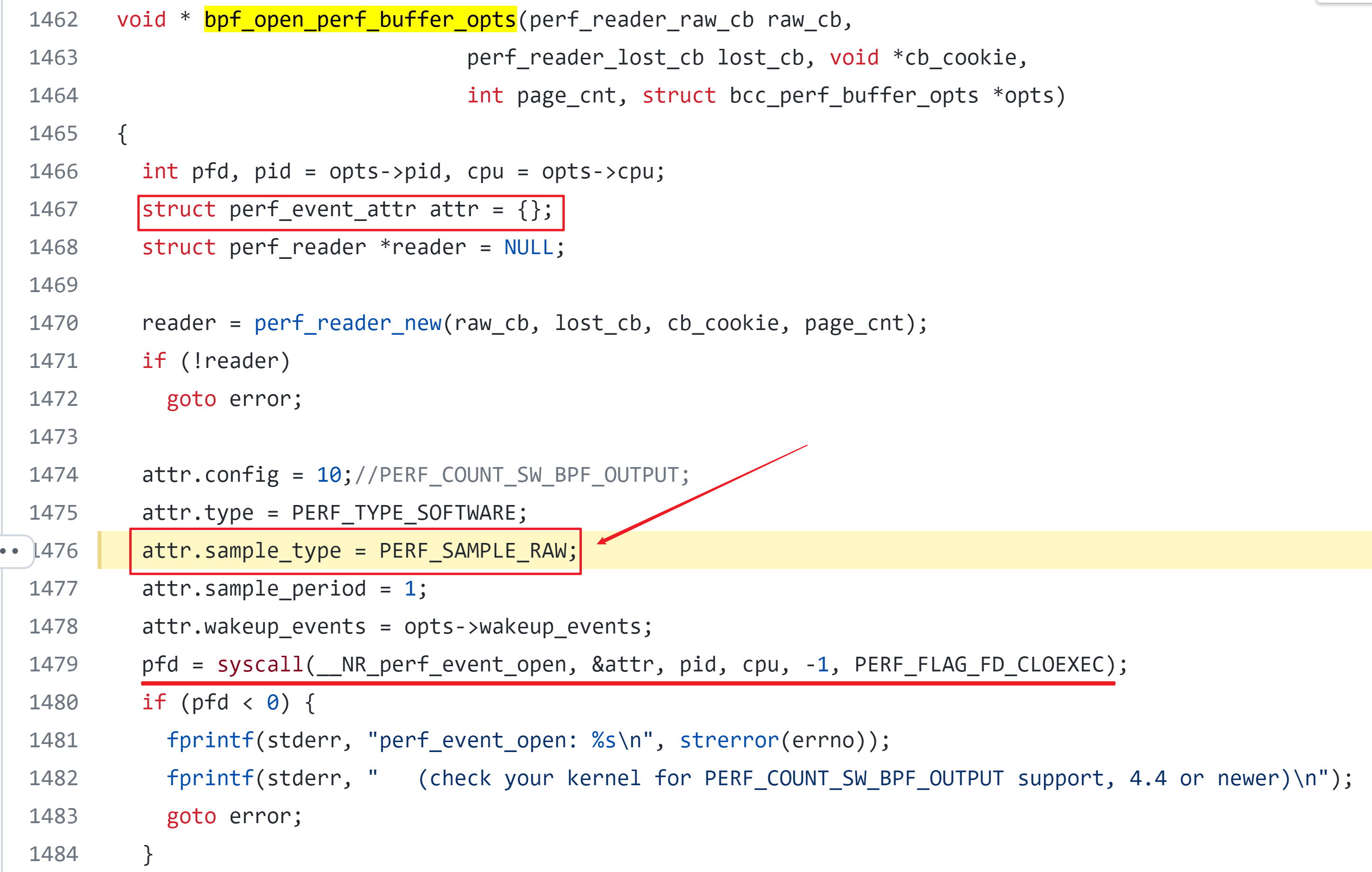
根据参考文章在src/cc/libbpf.c的bpf_open_perf_buffer_opts添加如下代码
if (opts->unwind_call_stack == 1) {
attr.sample_type |= PERF_SAMPLE_STACK_USER | PERF_SAMPLE_REGS_USER;
attr.sample_stack_user = 16384; // MAX=65528
attr.sample_regs_user = ((1ULL << 33) - 1);
attr.size = sizeof(struct perf_event_attr);
reader->is_unwind_call_stack = true;
}
这样一来内核返回数据的时候就会携带寄存器信息和用户空间栈数据了
内核返回数据构成
根据参考文章可知,内核返回的数据是PERF_RECORD_SAMPLE类型,而这种类型的构成具体可以参考libbpf的注释
在bcc调用perf_event_open时,对应指示了三种类型,那么返回的数据构造将满足下面的结构体
struct {
struct perf_event_header header;
u32 size; /* if PERF_SAMPLE_RAW */
char data[size]; /* if PERF_SAMPLE_RAW */
u64 abi; /* if PERF_SAMPLE_REGS_USER */
u64 regs[weight(mask)]; /* if PERF_SAMPLE_REGS_USER */
u64 size; /* if PERF_SAMPLE_STACK_USER */
char data[size]; /* if PERF_SAMPLE_STACK_USER */
u64 dyn_size; /* if PERF_SAMPLE_STACK_USER && size != 0 */
};其中regs[weight(mask)]到底是多大呢?
根据内核源码中mask就是前面修改bcc时设置的sample_regs_user
即((1 << 33) - 1) => 0x1ffffffff => 0b111111111111111111111111111111111
// private/msm-google/kernel/events/core.c perf_output_sample
if (sample_type & PERF_SAMPLE_REGS_USER) {
u64 abi = data->regs_user.abi;
perf_output_put(handle, abi);
if (abi) {
u64 mask = event->attr.sample_regs_user;
perf_output_sample_regs(handle, data->regs_user.regs, mask);
}
}结合perf_output_sample_regs中的代码,可以知道这里将发送33位寄存器,即arm64通用寄存器 + sp + pc
即regs[weight(mask)]就是regs[33]
// private/msm-google/kernel/events/core.c perf_output_sample_regs
static void perf_output_sample_regs(struct perf_output_handle *handle, struct pt_regs *regs, u64 mask) {
int bit;
DECLARE_BITMAP(_mask, 64);
bitmap_from_u64(_mask, mask);
for_each_set_bit(bit, _mask, sizeof(mask) * BITS_PER_BYTE) {
u64 val;
val = perf_reg_value(regs, bit);
(handle, val);
}
}返回的数据中PERF_SAMPLE_STACK_USER的data[size]又应该是多大呢?
还是结合内核源码来看,stack_user_size作为参数传给perf_output_sample_ustack
而对应的参数名为dump_size,结合代码可以知道该参数用来决定获取多少栈上的数据
而dyn_size指的是实际获取的栈数据大小
// private/msm-google/kernel/events/core.c perf_output_sample
if (sample_type & PERF_SAMPLE_STACK_USER) {
perf_output_sample_ustack(handle,
data->stack_user_size,
data->regs_user.regs);
}
// private/msm-google/kernel/events/core.c perf_output_sample_ustack
static void perf_output_sample_ustack(struct perf_output_handle *handle, u64 dump_size, struct pt_regs *regs) {
if (!regs) {
u64 size = 0;
perf_output_put(handle, size);
} else {
unsigned long sp;
unsigned int rem;
u64 dyn_size;
mm_segment_t fs;
perf_output_put(handle, dump_size);
sp = perf_user_stack_pointer(regs);
fs = get_fs();
set_fs(USER_DS);
rem = __output_copy_user(handle, (void *) sp, dump_size);
set_fs(fs);
dyn_size = dump_size - rem;
perf_output_skip(handle, rem);
perf_output_put(handle, dyn_size);
}
}小结一下
sample_type用于指示需要哪些类型的数据sample_regs_user用于指示需要多少个寄存器的数据,注意是二进制为1的数量sample_stack_user用于指示需要从栈上获取的数据最大大小
定制bcc
根据is_unwind_call_stack决定是否打印堆栈信息,注意这里的代码放在sanity check之前
为了可以正常通过sanity check,我们需要修正ptr
结合这里的上下文代码可以知道到sanity check的时候,正常情况下ptr是PERF_RECORD_SAMPLE数据末尾
对于设定is_unwind_call_stack为真的情况,我们指示还需要PERF_SAMPLE_REGS_USER和PERF_SAMPLE_STACK_USER两种类型的数据
u64 abi;u64 regs[weight(mask)];u64 size;char data[size];u64 dyn_size;
那么这部分的数据大小就是 => 16672 = 8 + 8 * 33 + 8 + 16384 + 8
static void parse_sw(struct perf_reader *reader, void *data, int size) {
// ...
if (reader->is_unwind_call_stack) {
int pid = *(int *)raw->data;
int write_size = ((uint8_t *)data + size) - ptr;
print_frame_info(pid, ptr, write_size);
// hack ptr
ptr += 16672;
}
// sanity check
// ...
}print_frame_info会依次发送pid、PERF_SAMPLE_REGS_USER和PERF_SAMPLE_STACK_USER数据、数据大小
注意,这里发送的pid是从PERF_SAMPLE_RAW中取出的,也就是说,编写bcc代码的时候,应当把perf_submit发送的数据对应结构体的第一位设置为pid值
bcc相关的完整修改请参考此commit
项目地址:
定制守护进程
虽然前面简单说了要实现的步骤,但是实践起来可能会有点困难
定制UnwindCallChain
UnwindCallChain实现如下,创建stack_memory使用的是unwindstack::Memory::CreateOfflineMemory
更期望可以得到符号信息,所以没有unwinder.SetResolveNames(false);
bool UnwindCallChain(int pid, uint64_t reg_mask, DataBuff *data_buf, int client_sockfd) {
RegSet regs(data_buf->user_regs.abi, reg_mask, data_buf->user_regs.regs);
LOG(DEBUG) << "abi:" << data_buf->user_regs.abi << ", arch:" << regs.arch;
uint64_t sp_reg_value;
if (!regs.GetSpRegValue(&sp_reg_value)) {
std::cerr << "can't get sp reg value";
return false;
}
LOG(DEBUG) << "sp_reg_value: 0x" << std::hex << sp_reg_value;
uint64_t stack_addr = sp_reg_value;
const char *stack = data_buf->user_stack.data;
size_t stack_size = data_buf->user_stack.dyn_size;
std::unique_ptr<unwindstack::Regs> unwind_regs(GetBacktraceRegs(regs));
if (!unwind_regs) {
return false;
}
std::shared_ptr<unwindstack::Memory> stack_memory = unwindstack::Memory::CreateOfflineMemory(
reinterpret_cast<const uint8_t*>(stack), stack_addr, stack_addr + stack_size
);
std::string map_buffer;
std::unique_ptr<unwindstack::Maps> maps;
std::string proc_map_file = "/proc/" + std::to_string(pid) + "/maps";
android::base::ReadFileToString(proc_map_file, &map_buffer);
maps.reset(new unwindstack::BufferMaps(map_buffer.c_str()));
maps->Parse();
unwindstack::Unwinder unwinder(512, maps.get(), unwind_regs.get(), stack_memory);
// default is true
// unwinder.SetResolveNames(false);
unwinder.Unwind();
std::string frame_info = DumpFrames(unwinder);
// LOG(DEBUG) << "frame_info:" << frame_info;
int len = frame_info.length();
send(client_sockfd, &len, 4, 0);
send(client_sockfd, frame_info.c_str(), len, 0);
return true;
}定制补充
根据前面的信息,我们已经知道了寄存器信息和用户栈空间数据的结构,那么定义以下结构体
struct UserRegs {
uint64_t abi;
uint64_t regs[33];
};
struct UserStack {
uint64_t size;
char data[16384];
uint64_t dyn_size;
};
struct DataBuff {
UserRegs user_regs;
UserStack user_stack;
};如此一来,便可以在接收到数据之后进行转换
另外硬编码了reg_mask,也就是前面设置的sample_regs_user,当然也可以通过socket传输
完整代码参见
优化与改进
目前的实现基本和参考文章是一致的,但是还有一些改进点
- 可以进一步定制bcc,在目标进程调用了
mmap等函数时才让守护进程重新获取一次maps信息 - 将守护进程改造为多线程支持
- 栈信息的打印改由python输出更统一
这里还需要强调一次的是,bcc写eBPF代码时,传递的数据的结构体第一个应当是pid
总结
基于AOSP开发获取用户态栈回溯信息的守护进程,并定制bcc,实现了两者联动
最终在eBPF中获取到准确详细的用户态堆栈信息
没有评论