这篇文章上次修改于 1022 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
前言
抓包看到wepkg的请求,咋一看是明文,但是格式又很奇怪,因为和wxapkg格式也不一样
结果搜索了一圈,似乎没有人有写过wepkg的解包,那么我来浅浅分析一下吧
微信版本:8.32
分析
hook下java.io.File.<init>,看看和wepkg相关的路径,调用栈如下:
Backtrace:
java.io.File.<init>(Native Method)
com.tencent.mm.vfs.NativeFileSystem$g.q(SourceFile:12)
com.tencent.mm.vfs.m.q(SourceFile:10)
com.tencent.mm.vfs.n1.q(SourceFile:18)
com.tencent.mm.plugin.wepkg.model.l.c(SourceFile:67)
m73.k.c(SourceFile:371)
m73.k.b(SourceFile:150)
m73.l.f(SourceFile:19)
m73.d.a(SourceFile:14)
xz.d.je0(SourceFile:24)
ow0.c.invokeSuspend(SourceFile:311)
ot3.a.resumeWith(SourceFile:9)
kotlinx.coroutines.DispatchedTask.run(SourceFile:123)
hp3.f.run(Unknown Source:2)
java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:463)
java.util.concurrent.FutureTask.run(FutureTask.java:264)
sp3.j.run(SourceFile:246)
java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1137)
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:637)
lp3.c.run(SourceFile:3)
java.lang.Thread.run(Thread.java:1012)查看com.tencent.mm.plugin.wepkg.model.l的反编译代码
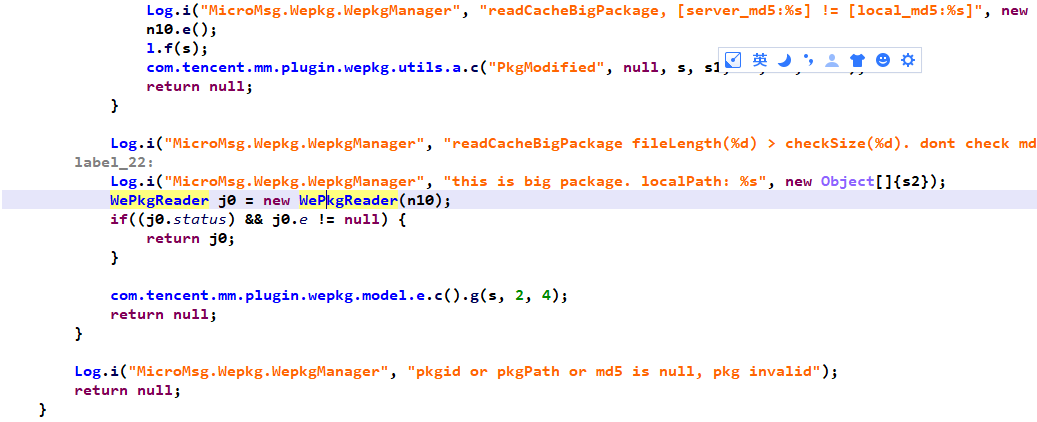
立刻定位到com.tencent.mm.plugin.wepkg.model.j,关键词是readCacheBigPackage和MicroMsg.Wepkg.WePkgReader
其中的关键代码如下:
fileChannel0.position(0L);
ByteBuffer byteBuffer0 = ByteBuffer.allocate(4);
byteBuffer0.order(WePkgReader.byteOrder);
fileChannel0.read(byteBuffer0);
this.next_item_size = byteBuffer0.getInt(0);
z = this.dealProtoData(fileChannel0);fileChannel0.position(4L);
ByteBuffer byteBuffer0 = ByteBuffer.allocate(this.next_item_size);
byteBuffer0.order(WePkgReader.byteOrder);
fileChannel0.read(byteBuffer0);
byte[] arr_b = byteBuffer0.array();
if(arr_b != null && arr_b.length != 0) {
this.e = new iu4();
this.e.parseFrom(arr_b);
this.f = this.e.resList;
this.d = 4 + this.next_item_size;
return true;
}结合进一步交叉引用和分析,确定了一个名为resList的字段
而根据经验,parseFrom这里是在解protobuf数据
具体分析一下代码逻辑,结合实际的protobuf数据,可以知道wepkg文件的构成大致如下:
- 前4字节表示protobuf数据大小
protobuf数据中实际上包含了多个文件的基本信息,比如:
- 归属链接
- 起始偏移(以protobuf数据末尾为起始)
- 文件实际大小
- 文件类型
- 跨域限制/或者是请求头信息
- 其他信息
- 多个连续的文件数据
目的是为了获取分离各个文件内容,于是在以上信息基础之上可以写出解包脚本,效果如下:
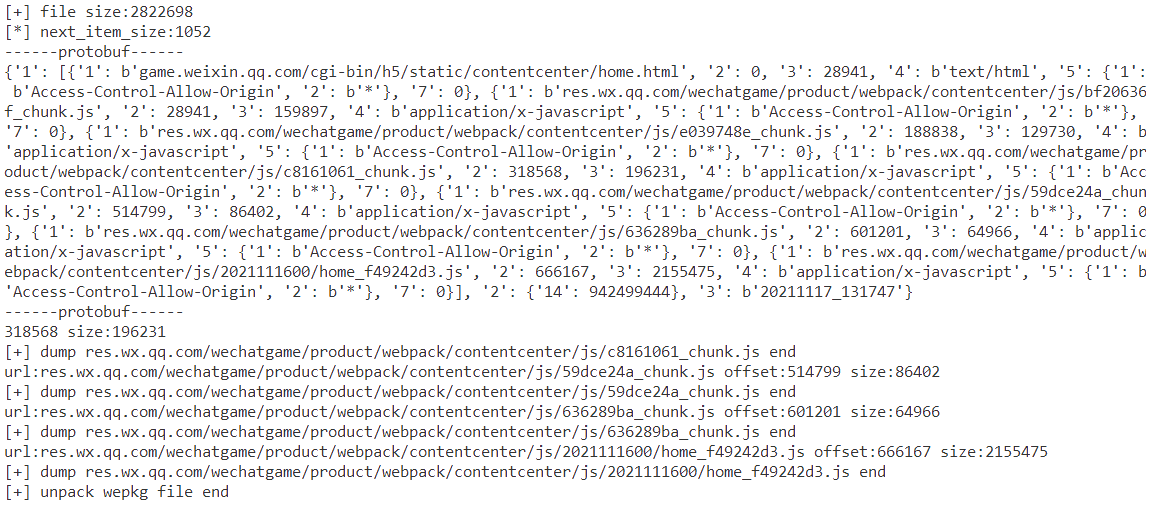
脚本
pip install blackboxprotobufimport shutil
import blackboxprotobuf
from pathlib import Path
def main():
def write_file(dump_path: Path, url: str, data: bytes):
next_path = dump_path
item_names = url.split('/')
for dir_name in item_names[:-1]:
next_path = next_path / dir_name
if not next_path.exists():
next_path.mkdir()
next_path = next_path / item_names[-1]
next_path.write_bytes(data)
print(f'[+] dump {url} end')
pkg = Path(r'pkg_p101944_v10253.wepkg')
data = pkg.read_bytes()
print(f'[+] file size:{len(data)}')
next_item_size = int.from_bytes(data[:4], byteorder='big')
print(f'[*] next_item_size:{next_item_size}')
proto_data = data[4:next_item_size + 4]
message, typedef = blackboxprotobuf.decode_message(proto_data)
print('------protobuf------')
print(message)
print('------protobuf------')
payload_offset = next_item_size + 4
# for k, v in message.items():
# print(k, v)
res_list = message['1']
if len(res_list) > 0:
dump_path = Path(pkg.parent) / 'wepkg_dump'
if dump_path.exists():
shutil.rmtree(dump_path.resolve().as_posix())
print('[+] delete wepkg_dump')
dump_path.mkdir()
json_data, typedef = blackboxprotobuf.protobuf_to_json(proto_data)
info_path = dump_path / 'info.json'
info_path.write_text(json_data, encoding='utf-8')
print('[+] save wepkg info')
for res in res_list:
url = res['1'].decode('utf-8')
offset = res['2']
size = res['3']
# mime = res['4'].decode('utf-8')
# headers = res['5']
print(f'url:{url} offset:{offset} size:{size}')
start = payload_offset + offset
end = start + size
payload = data[start:end]
write_file(dump_path, url, payload)
print(f'[+] unpack wepkg file end')
if __name__ == '__main__':
main()
没有评论