这篇文章上次修改于 1770 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
原文 -> https://blog.csdn.net/qq_38851536/article/details/117828334
前言
久违了,这是SO逆向实战教程的第五篇,最近忙于即将开讲的Unidbg课程内容的设计,所以疏忽了博客的更新,这篇的重点是一个MD5的炫技操作,需要对哈希算法原理有较深理解,本篇中不讲算法原理(可以自己看文档,或者看我在SO基础课里对MD5算法的手算),不懂算法原理的话,看起来一头雾水
这是SO逆向入门实战教程的第五篇,总共会有十三篇,十三个实战。有以下几个注意点:
- 主打入门级的实战,适合有一定基础但缺少实战的朋友(了解JNI,也上过一些Native层逆向的课,但感觉实战匮乏,想要壮壮胆,入入门)。
- 侧重新工具、新思路、新方法的使用,算法分析的常见路子是Frida Hook + IDA ,在本系列中,会淡化Frida 的作用,采用Unidbg Hook + IDA 的路线。
- 主打入门,但并不限于入门,你会在样本里看到有浅有深的魔改加密算法、以及OLLVM、SO对抗等内容。
- 共十三篇,1-2天更新一篇。每篇的资料放在文末的百度网盘中。
准备
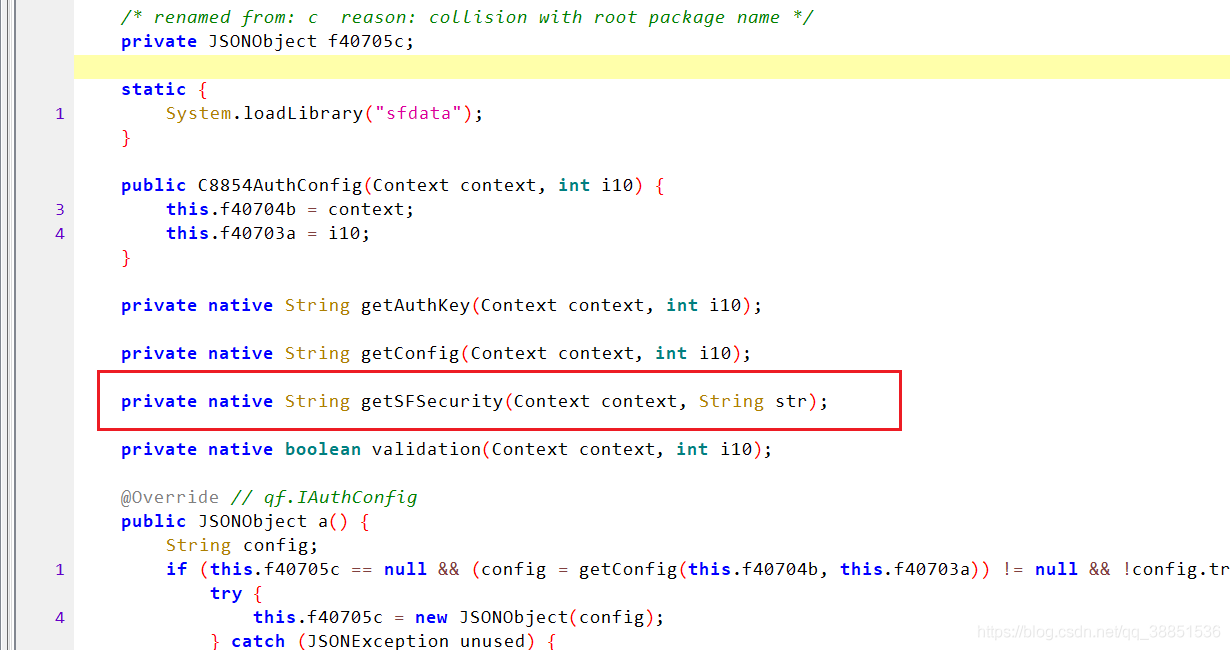
只有两个参数,context和明文,结果是一长串
输入与输出示例
- input1 -> context
- input2 -> r0ysue
- output -> nonce=32DAB5DB-A036-4B83-8884-1E95A552C4B2×tamp=1623412271283&devicetoken=r0ysue&sign=5B0FF50A89C8704E3B3149A9E0EF2679
可以发现,输出的就是devicetoken,在输出中,有nonce和sign两个未知的键值对,timestamp应该就只是时间戳
unidbg模拟执行
package com.lession5;
import com.github.unidbg.AndroidEmulator;
import com.github.unidbg.Module;
import com.github.unidbg.linux.android.AndroidEmulatorBuilder;
import com.github.unidbg.linux.android.AndroidResolver;
import com.github.unidbg.linux.android.dvm.*;
import com.github.unidbg.memory.Memory;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.PrintStream;
import java.util.ArrayList;
import java.util.List;
public class qxs extends AbstractJni{
private final AndroidEmulator emulator;
private final VM vm;
private final Module module;
qxs() throws FileNotFoundException {
emulator = AndroidEmulatorBuilder.for32Bit().setProcessName("com.qxs").build(); // 创建模拟器实例,要模拟32位或者64位,在这里区分
final Memory memory = emulator.getMemory(); // 模拟器的内存操作接口
memory.setLibraryResolver(new AndroidResolver(23)); // 设置系统类库解析
vm = emulator.createDalvikVM(new File("unidbg-android\\src\\test\\java\\com\\lession5\\轻小说.apk")); // 创建Android虚拟机
vm.setVerbose(true); // 设置是否打印Jni调用细节
DalvikModule dm = vm.loadLibrary(new File("unidbg-android\\src\\test\\java\\com\\lession5\\libsfdata.so"), false); // 加载libttEncrypt.so到unicorn虚拟内存,加载成功以后会默认调用init_array等函数
module = dm.getModule(); //
// 先把JNI Onload跑起来,里面做了大量的初始化工作
vm.setJni(this);
dm.callJNI_OnLoad(emulator);
}
public static void main(String[] args) throws Exception {
qxs test = new qxs();
System.out.println(test.getSFsecurity());
}
public String getSFsecurity(){
List<Object> list = new ArrayList<>(10);
list.add(vm.getJNIEnv()); // 第一个参数是env
list.add(0); // 第二个参数,实例方法是jobject,静态方法是jclazz,直接填0,一般用不到
Object custom = null;
DvmObject<?> context = vm.resolveClass("android/content/Context").newObject(custom);// context
list.add(vm.addLocalObject(context));
list.add(vm.addLocalObject(new StringObject(vm, "F1517503-9779-32B7-9C78-F5EF501102BC")));
Number number = module.callFunction(emulator, 0xA944 + 1, list.toArray())[0];
String result = vm.getObject(number.intValue()).getValue().toString();
return result;
}
}运行异常补环境
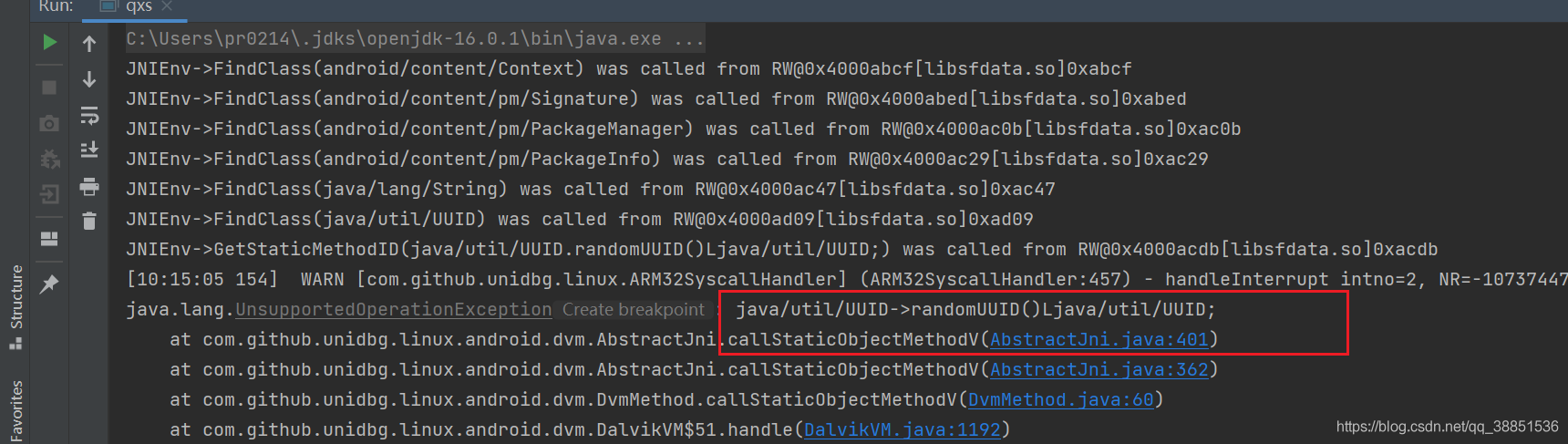
@Override
public DvmObject<?> callStaticObjectMethodV(BaseVM vm, DvmClass dvmClass, String signature, VaList vaList) {
switch (signature) {
case "java/util/UUID->randomUUID()Ljava/util/UUID;":{
return dvmClass.newObject(UUID.randomUUID());
}
}
return super.callStaticObjectMethodV(vm, dvmClass, signature, vaList);
};运行异常补环境
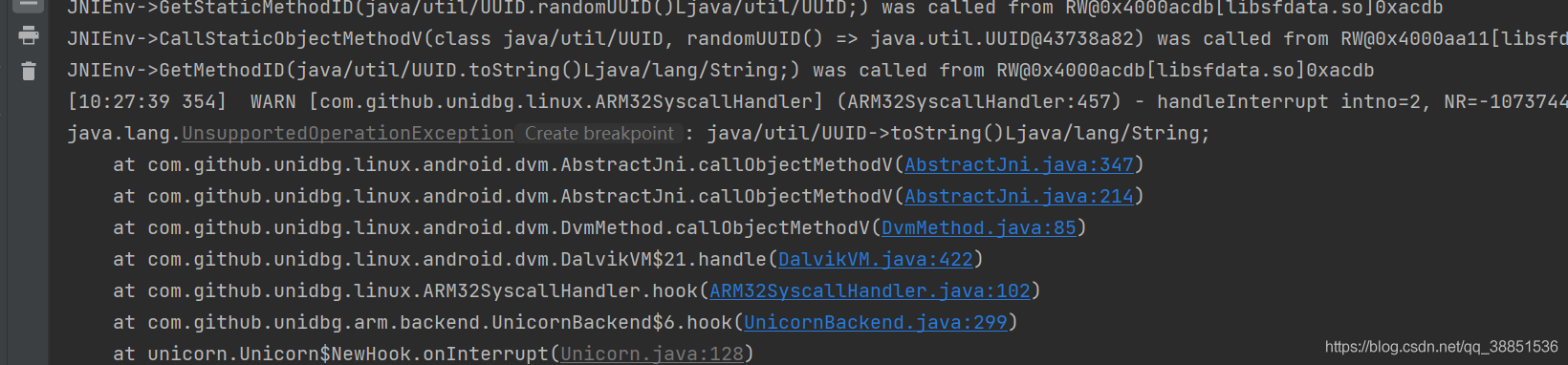
@Override
public DvmObject<?> callObjectMethodV(BaseVM vm, DvmObject<?> dvmObject, String signature, VaList vaList) {
switch (signature) {
case "java/util/UUID->toString()Ljava/lang/String;":{
String uuid = dvmObject.getValue().toString();
return new StringObject(vm, uuid);
}
}
return super.callObjectMethodV(vm, dvmObject, signature, vaList);
}出结果
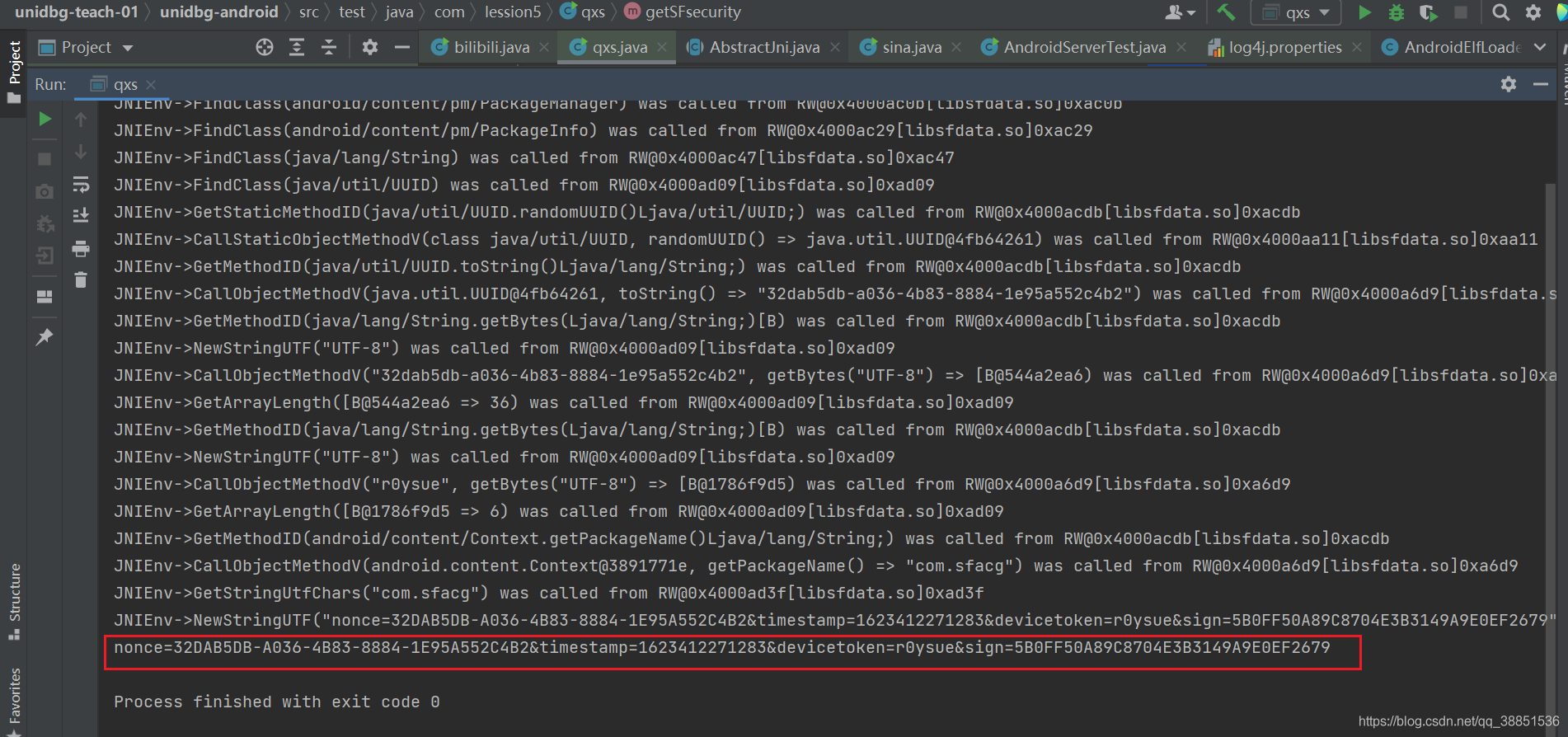
验证可以发现,nonce即uuid生成的随机数,timestamp就是当前时间戳,deviceToken就是传入的参数,sign就是生成的结果
问题来了,sign哪来的
算法还原
这个SO存在一定的保护,没办法通过F5反编译,findHash插件也没有给出结果,那该怎么办?
这让人不禁思考一个问题
unidbg已经把加密结果正确跑出来了,那么,这个算法的所有细节应该尽收眼底,可是为什么现在emmm
我们连它用了什么加密都一无所知呢?这显然是不合理的呀!
让我们打开unidbg 的traceCode功能,追踪一下汇编指令流
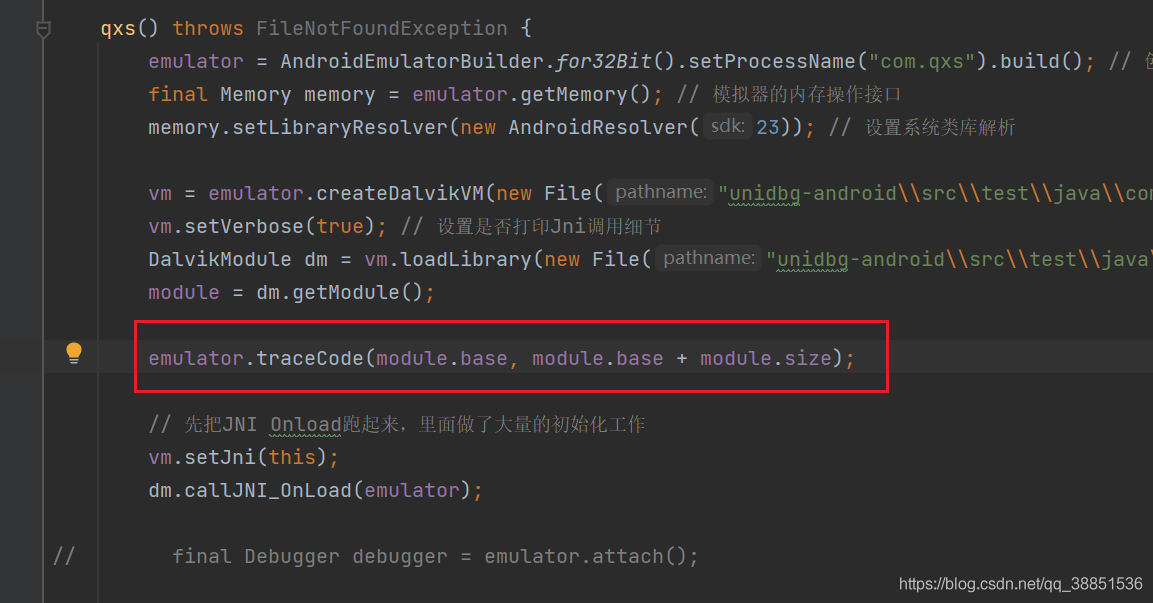
参数是起始地址和终止地址,此处指只追踪SO内的汇编流程,我们并不想跟着去libc里
运行代码,这次足足跑了一两分钟才出结果
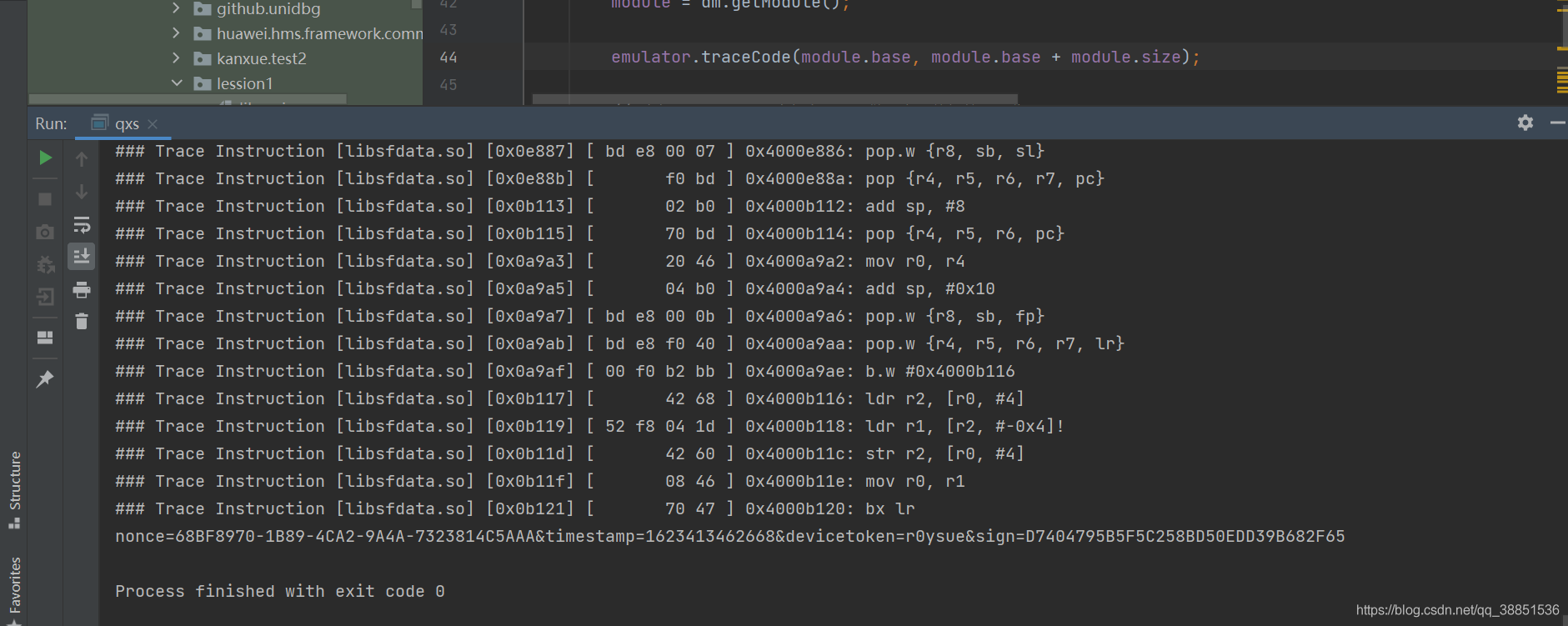
我们将trace的汇编执行流保存到文件中,这样更直观,也好分析
// 保存的path
String traceFile = "unidbg-android\\src\\test\\java\\com\\lession5\\qxstrace.txt";
PrintStream traceStream = new PrintStream(new FileOutputStream(traceFile), true);
emulator.traceCode(module.base, module.base+module.size).setRedirect(traceStream);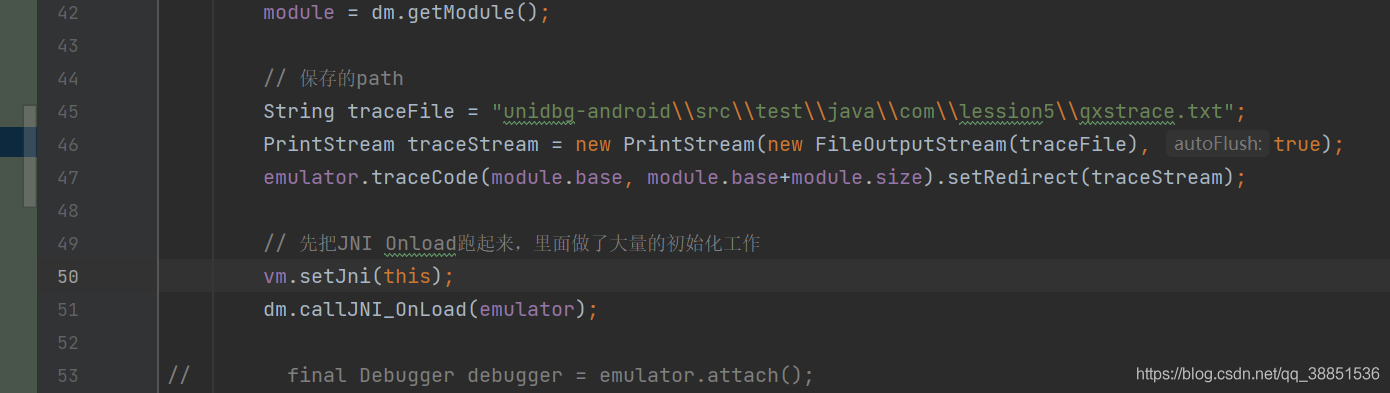
运行完成后,查看trace文件
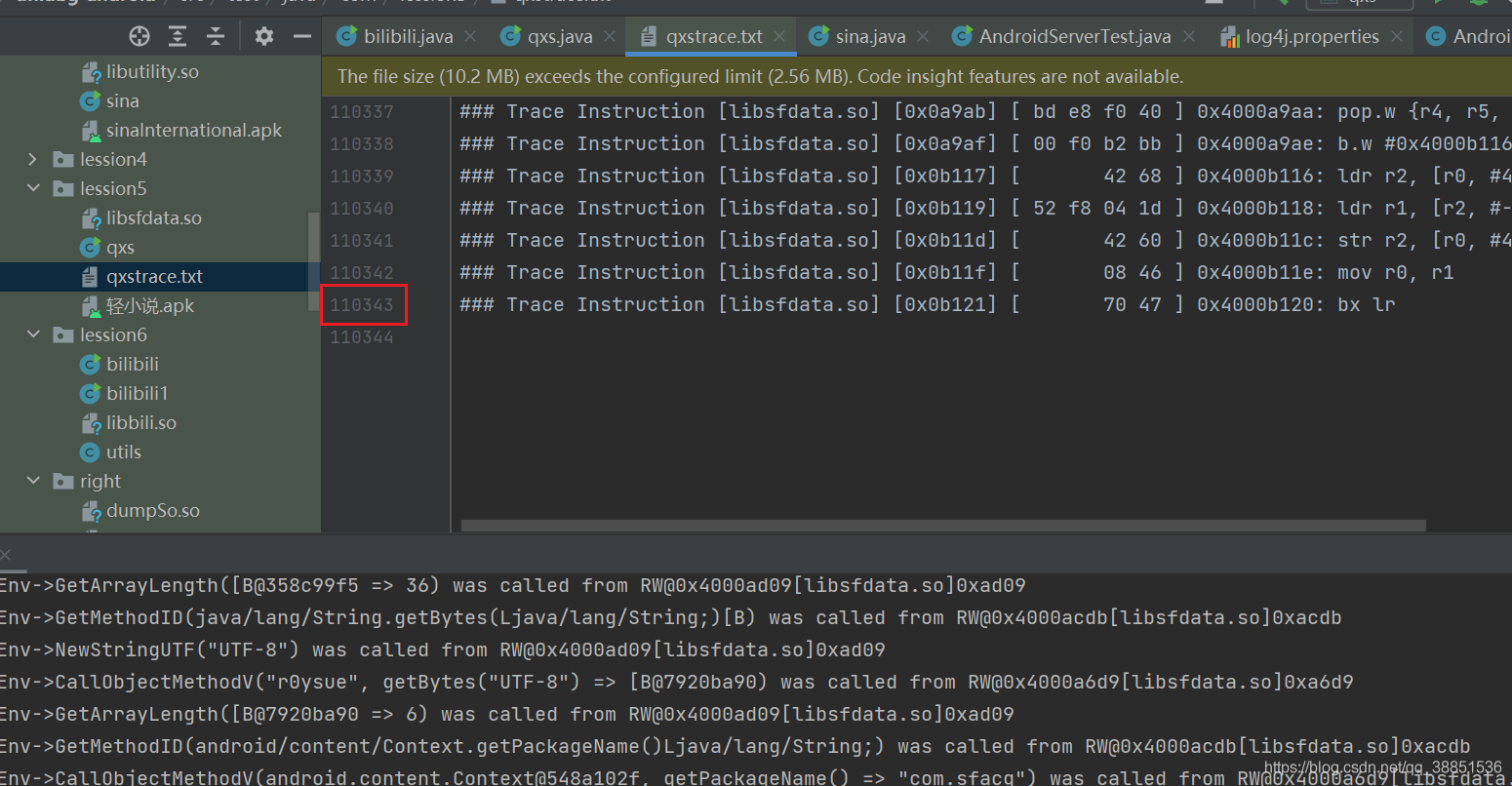
trace文件共11w行,但我们对这个trace其实并不满意,相比较IDA trace,它少了非常关键的寄存器值信息
在指令trace这方面,ExAndroidNativeemu做的非常好,我们后面会做一下分析,现在我们先简单实现一下unidbg的指令trace(ARM32)
找到代码文件 src/main/java/com/github/unidbg/arm/AbstractARMEmulator.java
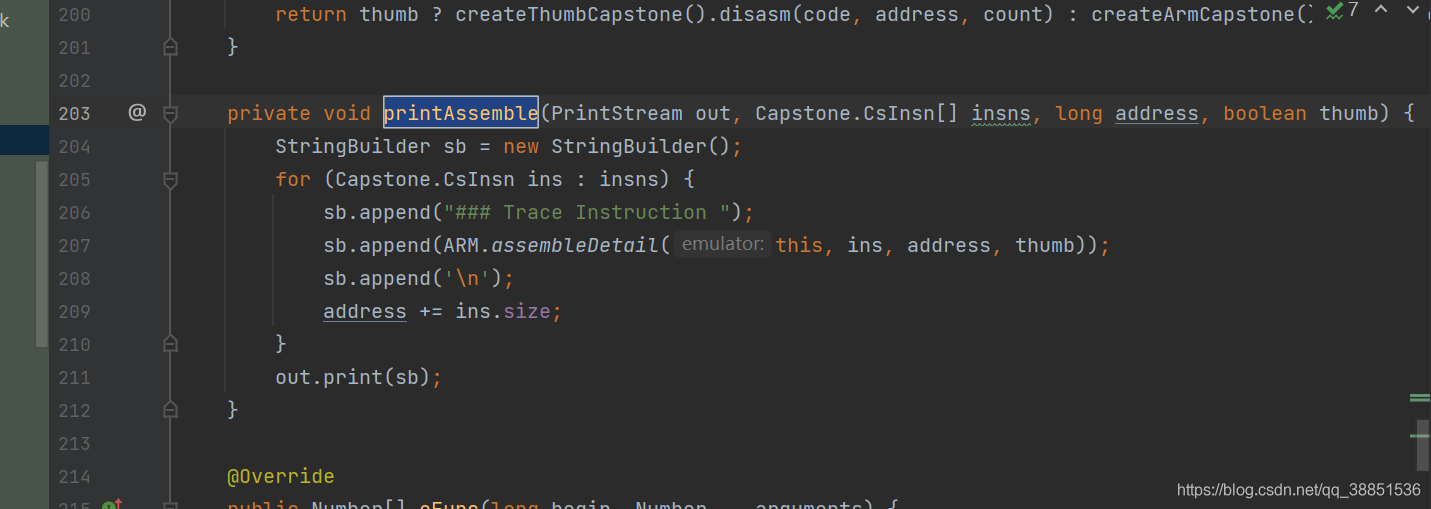
// 添加值显示
private void printAssemble(PrintStream out, Capstone.CsInsn[] insns, long address, boolean thumb) {
StringBuilder sb = new StringBuilder();
for (Capstone.CsInsn ins : insns) {
sb.append("### Trace Instruction ");
sb.append(ARM.assembleDetail(this, ins, address, thumb));
// 打印每条汇编指令里参与运算的寄存器的值
Set<Integer> regset = new HashSet<Integer>();
Arm.OpInfo opInfo = (Arm.OpInfo) ins.operands;
for(int i = 0; i<opInfo.op.length; i++){
regset.add(opInfo.op[i].value.reg);
}
String RegChange = ARM.SaveRegs(this, regset);
sb.append(RegChange);
sb.append('\n');
address += ins.size;
}
out.print(sb);
}src/main/java/com/github/unidbg/arm/ARM.java中,新建SaveRegs方法
实际上就是showregs的代码,只不过从print改成return回来而已
public static String SaveRegs(Emulator<?> emulator, Set<Integer> regs) {
Backend backend = emulator.getBackend();
StringBuilder builder = new StringBuilder();
builder.append(">>>");
Iterator it = regs.iterator();
while(it.hasNext()) {
int reg = (int) it.next();
Number number;
int value;
switch (reg) {
case ArmConst.UC_ARM_REG_R0:
number = backend.reg_read(reg);
value = number.intValue();
builder.append(String.format(Locale.US, " r0=0x%x", value));
break;
case ArmConst.UC_ARM_REG_R1:
number = backend.reg_read(reg);
value = number.intValue();
builder.append(String.format(Locale.US, " r1=0x%x", value));
break;
case ArmConst.UC_ARM_REG_R2:
number = backend.reg_read(reg);
value = number.intValue();
builder.append(String.format(Locale.US, " r2=0x%x", value));
break;
case ArmConst.UC_ARM_REG_R3:
number = backend.reg_read(reg);
value = number.intValue();
builder.append(String.format(Locale.US, " r3=0x%x", value));
break;
case ArmConst.UC_ARM_REG_R4:
number = backend.reg_read(reg);
value = number.intValue();
builder.append(String.format(Locale.US, " r4=0x%x", value));
break;
case ArmConst.UC_ARM_REG_R5:
number = backend.reg_read(reg);
value = number.intValue();
builder.append(String.format(Locale.US, " r5=0x%x", value));
break;
case ArmConst.UC_ARM_REG_R6:
number = backend.reg_read(reg);
value = number.intValue();
builder.append(String.format(Locale.US, " r6=0x%x", value));
break;
case ArmConst.UC_ARM_REG_R7:
number = backend.reg_read(reg);
value = number.intValue();
builder.append(String.format(Locale.US, " r7=0x%x", value));
break;
case ArmConst.UC_ARM_REG_R8:
number = backend.reg_read(reg);
value = number.intValue();
builder.append(String.format(Locale.US, " r8=0x%x", value));
break;
case ArmConst.UC_ARM_REG_R9: // UC_ARM_REG_SB
number = backend.reg_read(reg);
value = number.intValue();
builder.append(String.format(Locale.US, " sb=0x%x", value));
break;
case ArmConst.UC_ARM_REG_R10: // UC_ARM_REG_SL
number = backend.reg_read(reg);
value = number.intValue();
builder.append(String.format(Locale.US, " sl=0x%x", value));
break;
case ArmConst.UC_ARM_REG_FP:
number = backend.reg_read(reg);
value = number.intValue();
builder.append(String.format(Locale.US, " fp=0x%x", value));
break;
case ArmConst.UC_ARM_REG_IP:
number = backend.reg_read(reg);
value = number.intValue();
builder.append(String.format(Locale.US, " ip=0x%x", value));
break;
case ArmConst.UC_ARM_REG_SP:
number = backend.reg_read(reg);
value = number.intValue();
builder.append(String.format(Locale.US, " SP=0x%x", value));
break;
case ArmConst.UC_ARM_REG_LR:
number = backend.reg_read(reg);
value = number.intValue();
builder.append(String.format(Locale.US, " LR=0x%x", value));
break;
case ArmConst.UC_ARM_REG_PC:
number = backend.reg_read(reg);
value = number.intValue();
builder.append(String.format(Locale.US, " PC=0x%x", value));
break;
}
}
return builder.toString();
}代码存在一些小bug,但勉强能用,让我们来看一下结果
Sign是三十二位十六进制数,这让人想到MD5
MD5在前面的篇幅中已经讲了很多了,它有两组标志性的数可以用于确认自身身份
1.是0x67452301 0xefcdab89 等四个魔术,但单靠这四个数证明不了是MD5,也可能是别的哈希算法,除此之外,算法可能魔改常数
2.MD5的64个K,K1-K64是MD5独特的标志,简单的魔改也不会改K值(其实K表也可以随便改,但一般的开发人员也不懂K的意义,不敢乱改)
# 魔数
A = 0x67452301
B = 0xefcdab89
C = 0x98badcfe
D = 0x10325476
# K表
Ktable = [
0xd76aa478, 0xe8c7b756, 0x242070db, 0xc1bdceee, 0xf57c0faf,
0x4787c62a, 0xa8304613, 0xfd469501, 0x698098d8, 0x8b44f7af,
0xffff5bb1, 0x895cd7be, 0x6b901122, 0xfd987193, 0xa679438e,
0x49b40821, 0xf61e2562, 0xc040b340, 0x265e5a51, 0xe9b6c7aa,
0xd62f105d, 0x2441453, 0xd8a1e681, 0xe7d3fbc8, 0x21e1cde6,
0xc33707d6, 0xf4d50d87, 0x455a14ed, 0xa9e3e905, 0xfcefa3f8,
0x676f02d9, 0x8d2a4c8a, 0xfffa3942, 0x8771f681, 0x6d9d6122,
0xfde5380c, 0xa4beea44, 0x4bdecfa9, 0xf6bb4b60, 0xbebfbc70,
0x289b7ec6, 0xeaa127fa, 0xd4ef3085, 0x4881d05, 0xd9d4d039,
0xe6db99e5, 0x1fa27cf8, 0xc4ac5665, 0xf4292244, 0x432aff97,
0xab9423a7, 0xfc93a039, 0x655b59c3, 0x8f0ccc92, 0xffeff47d,
0x85845dd1, 0x6fa87e4f, 0xfe2ce6e0, 0xa3014314, 0x4e0811a1,
0xf7537e82, 0xbd3af235, 0x2ad7d2bb, 0xeb86d391
]看一下汇编trace文件

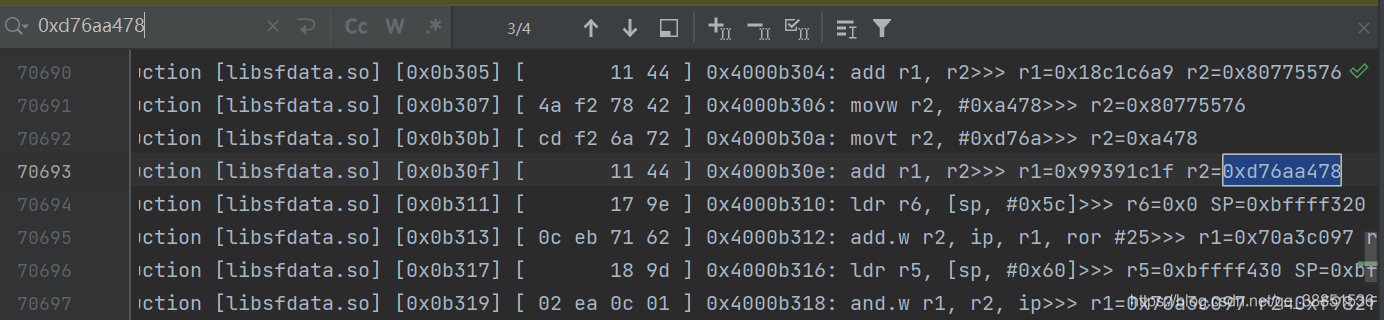
可以搜索到K表中的值以及魔数,所以可以断定是一个MD5或者MD5的魔改版本
考虑一个问题,我们是否可以直接从汇编中"析出"明文和密文?实际上对于标准算法来说是完全可以的,接下来的思路需要对MD5算法具有较深的了解
首先,我们明确了样本算法中使用到了MD5
接下来我们做两件事
- 从汇编trace中析出MD5的结果——用于确认输出是否与MD5有直接关系
- 从汇编trace中析出MD5的输入——用于确认函数的输入和MD5的输入的关系
首先做第一件事
找0x67452301最后和谁相加
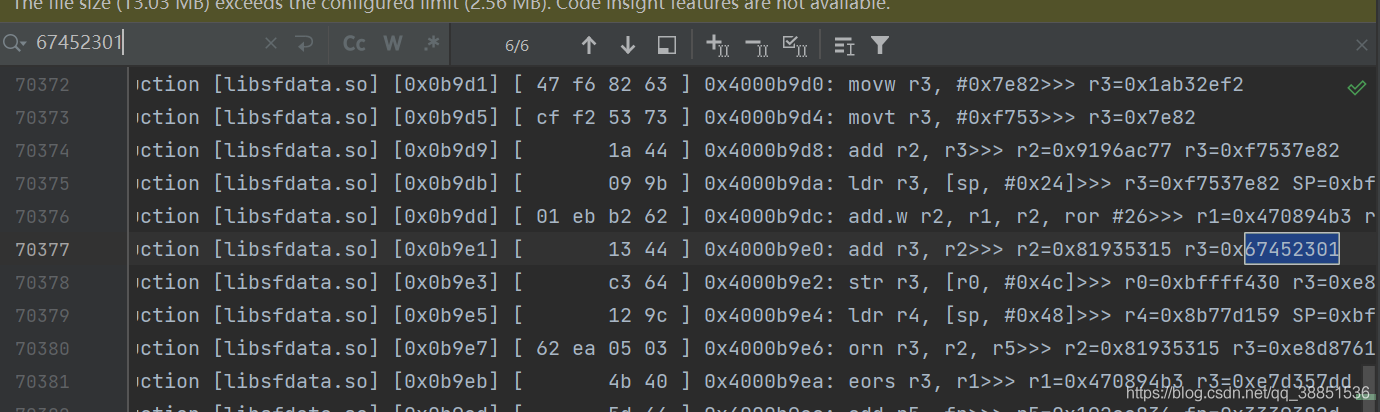
计算两者相加的结果(如果大于0xffffffff则取低的32比特) 即 E8D87616
如果输入小于512比特,那么调整一下端序,1676D8E8,这就是MD5前8个数字的结果
我们搜索一下 E8D87616,发现后面还有它参与的运算,这说明明文长度超过一个分组长,需要进行第二个分组的运算
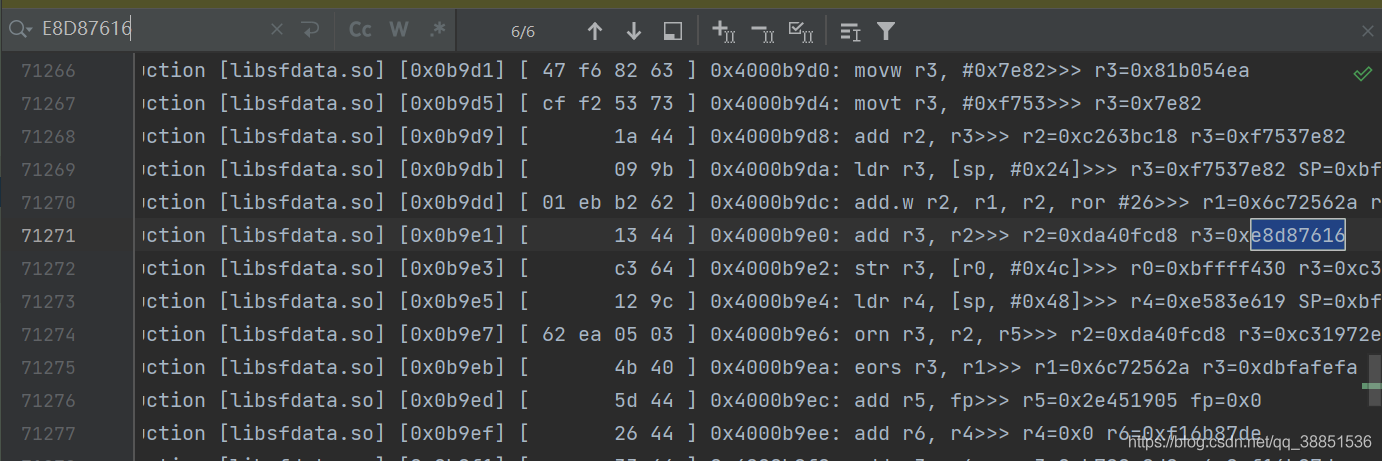
同样找0xE8D87616最后和谁相加
0xE8D87616 + 0xda40fcd8
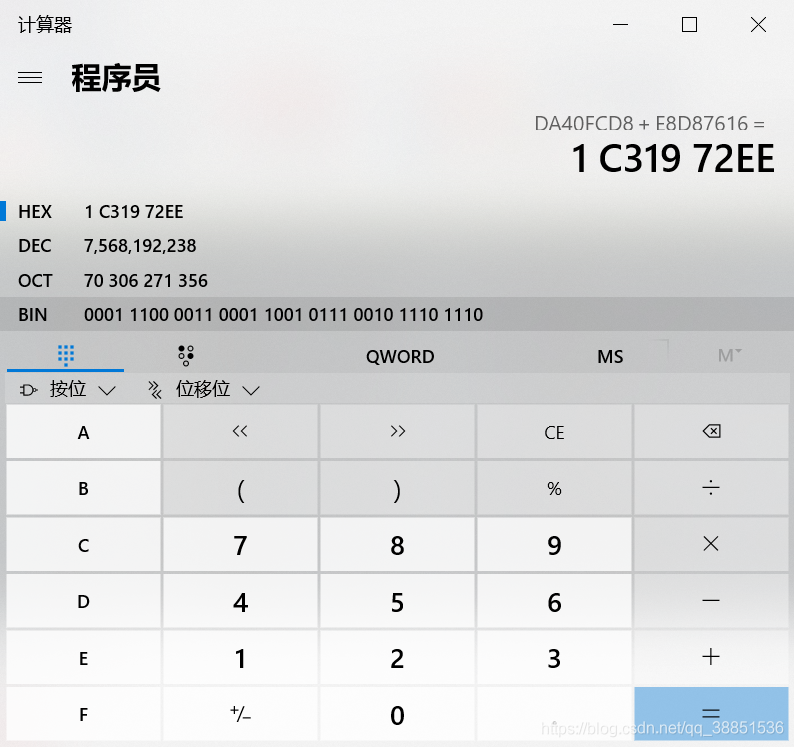
取C319 72EE
倒转端序 即EE72 19C3
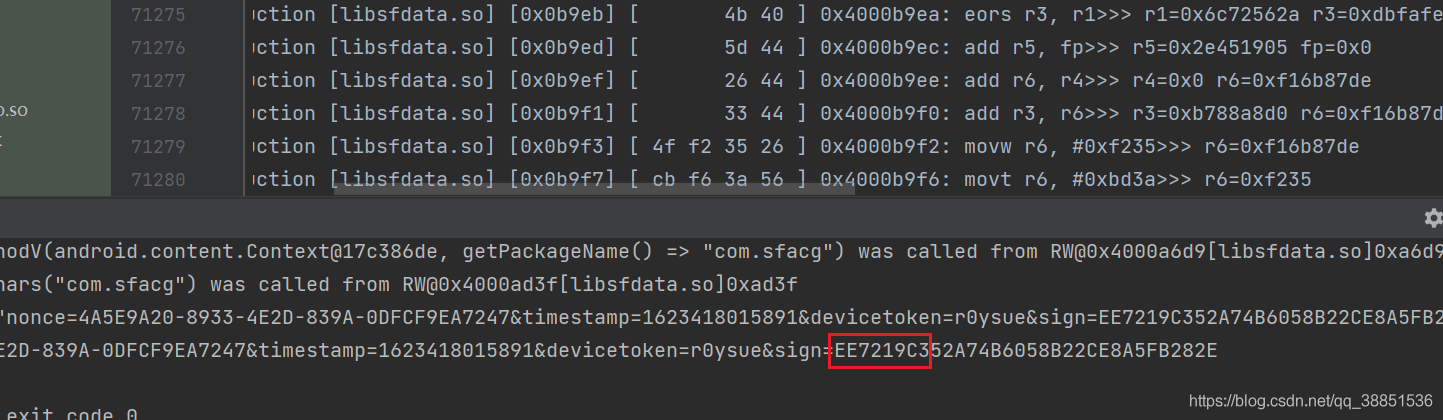
我们发现这就是加密结果的前8个数,读者可以自行验证第二第三第四部分,同理
我们通过这种方式确认了,MD5的结果就是加密的结果
那么做另一件事——Trace汇编中析出MD5的明文,这不是一件简单的事
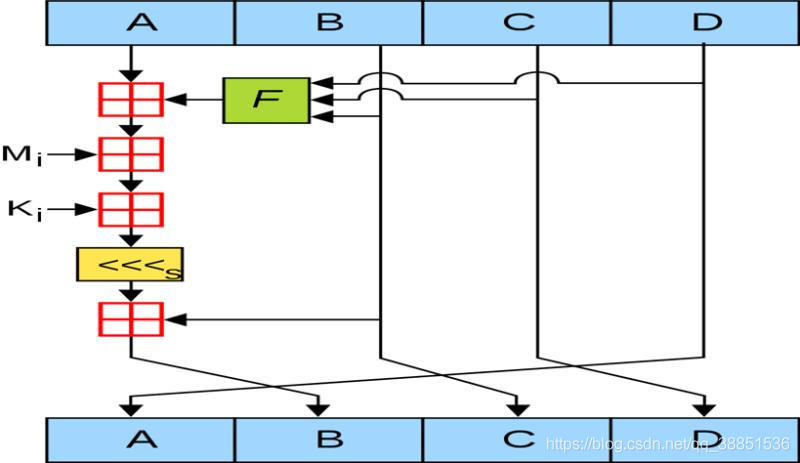
在MD5具体流程中,每轮运算都需要64步,每步的第三个操作是选取明文的一截进行加法运算,第四个操作是和K相加
我们无法定位第三个操作,但因为第四个操作的K都是已知的
所以可以这样描述
- 第四个操作上方第一个add运算就是明文的一截+中间结果
但是呢...
这前四步其实并没有硬性的顺序要求,生成的汇编代码常常不遵照顺序
但好在第一个F(B,C,D)的结果是固定的0xffffffff,它是一个很好的锚点
基于K值和这个锚点,我们可以在汇编trace中准确的析出明文——仅依靠trace汇编
不管OLLVM或者花指令将指令流变成10w行还是100w行,还是SO做了保护,明文不会完整出现在内存中,都不影响这个分析过程
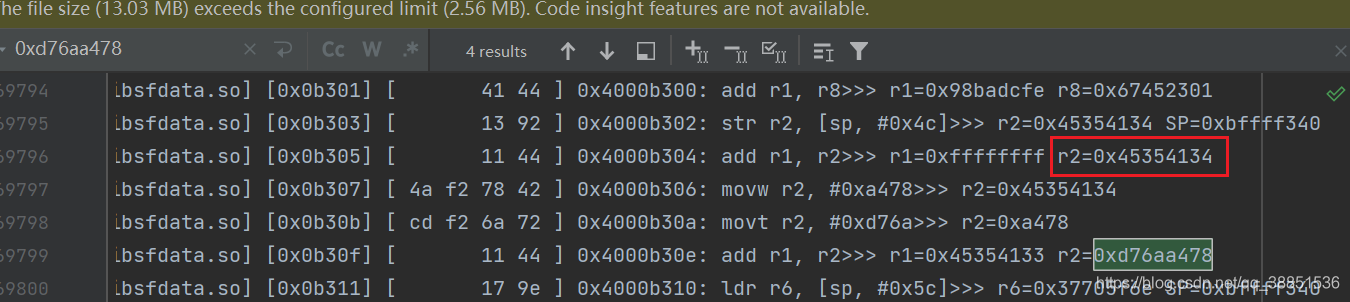
红框即定位的明文块1的小端序
所以明文就是34413545,cyberchef中看一下
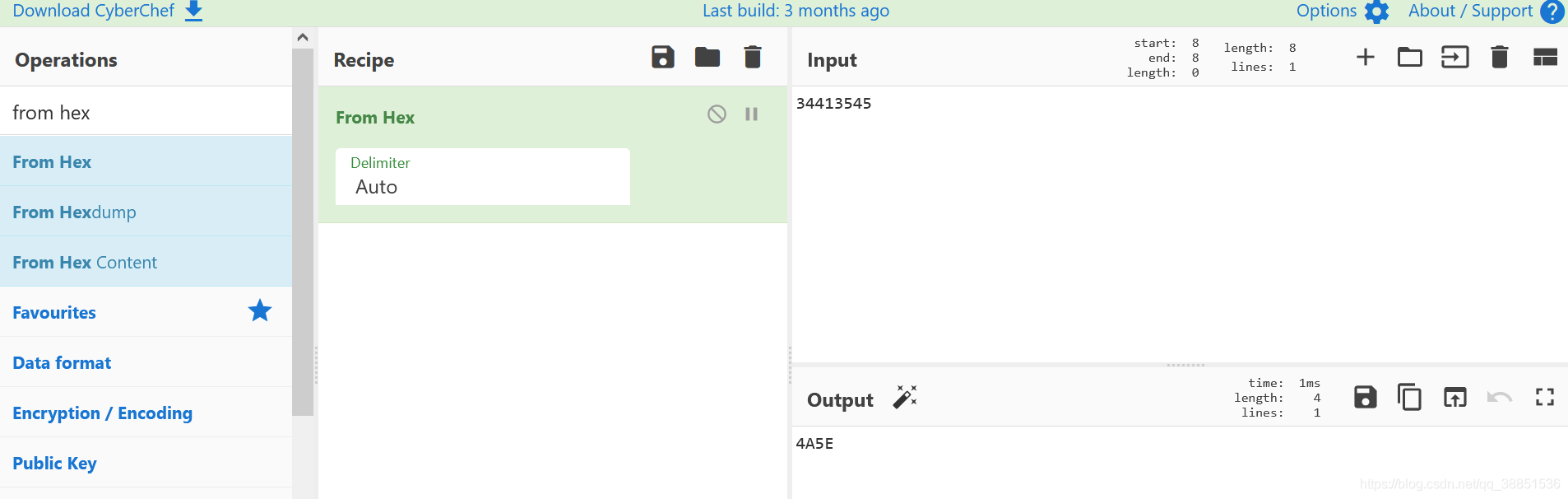
依照着所述锚点,不断往下追
- 第一个明文块:4A5E
- 第二个明文块:9A20
- 第三个明文块:-893
- 第四个明文块:3-4E
- 第五个明文块:2D-8
- 第六个明文块:39A-
- 第七个明文块:0DFC
- 第八个明文块:F9EA
- 第九个明文块:7247
- 第十个明文块:1623
- 第十一个明文块:4180
- 第十二个明文块:1589
- 第十三个明文块:1r0y
- 第十四个明文块:suet
- 第十五个明文块:d9#K
- 第十六个明文块:n_p7
开始第二个分组
- 第十七个明文块:vUw.(.即0x80填充开始)
更严谨些,通过K15确认明文长0x218比特,即512比特+ 24比特,所以明文到此结束,合并起来就是
- 4A5E9A20-8933-4E2D-839A-0DFCF9EA72471623418015891r0ysuetd9#Kn_p7vUw
首先迫不及待求一下MD5,验证结果
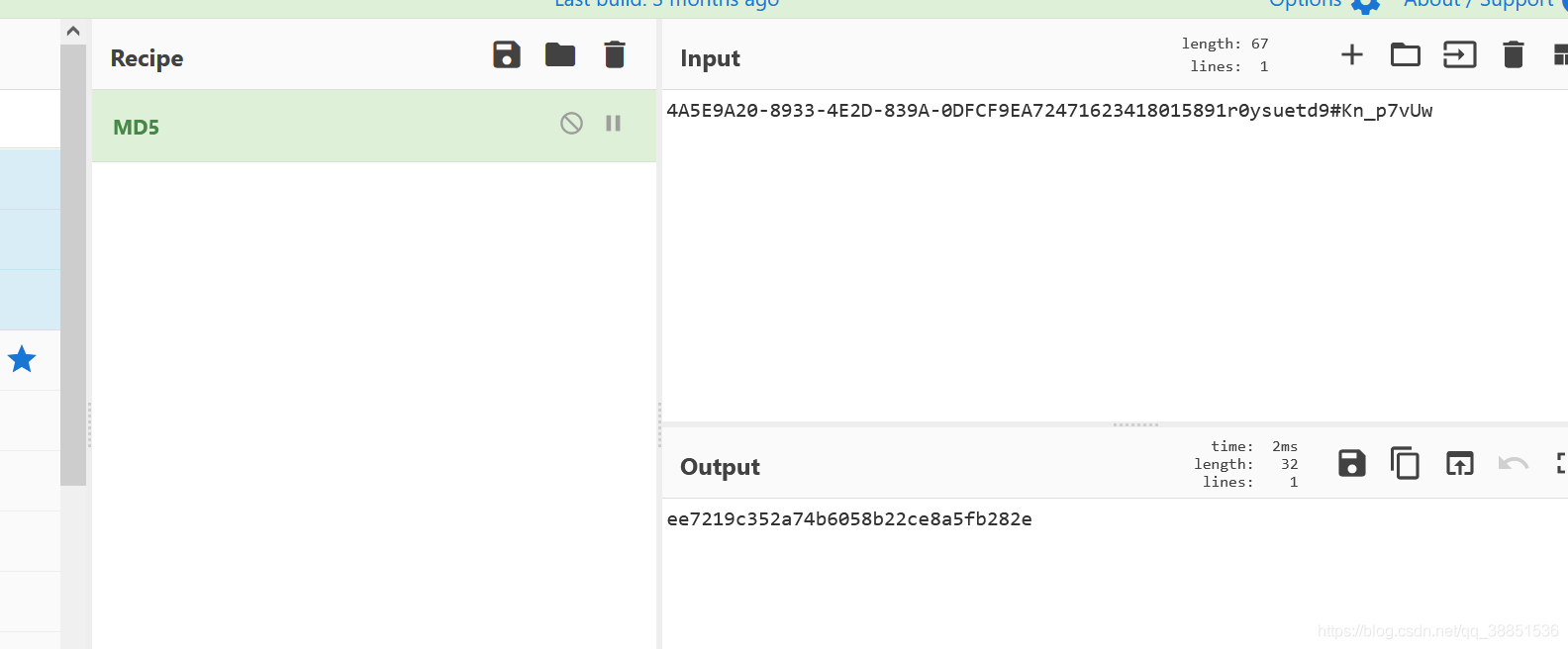
完全正确
接下来仔细瞧瞧明文的组成
这是我们的输出
nonce=4A5E9A20-8933-4E2D-839A-0DFCF9EA7247×tamp=1623418015891&devicetoken=r0ysue&sign=EE7219C352A74B6058B22CE8A5FB282E
这是明文
4A5E9A20-8933-4E2D-839A-0DFCF9EA72471623418015891r0ysuetd9#Kn_p7vUw
即
- nonce+timestamp+devicetoken+(固定的salt)td9#Kn_p7vUw
大功告成!
尾声
这不是一篇简单的文章,放第五篇有些偏前,而且其方法内核基于加密算法的深度理解,看不懂或者看不下去都没关系,下一篇恢复正常,和此篇没有关联性
但笔者必须要强调,文中所述的这种方法,是一种强大的、无视混淆流程的,真正意义上深入底层的标准算法还原技术
尤其在加盐哈希算法中分析盐格外强大,甚至存在编写代码自动化完成相关工作的可能性
资源链接:https://pan.baidu.com/s/1b24egt-FEbcRlQYeOwpNYQ
提取码:1t4l
没有评论